Translating Software Strings and Translating documentation
I remember seeing a post on LinkedIn from a Translation Management System developer stating that translating software strings and translating documentation are the same thing.
This is not accurate. Software strings are very different from those in documentation and need to be treated differently during the localization process and in a Translation Management System.
I have often been asked by software developers to run leverages from translated UI strings to documentation and online help. The leverage from such an exercise is really small, to their surprise always in the single percentages. UI strings are short, one to five words making up the maximum text. Documentation or online help is much more verbose. TM segmentation works on the basis of analyzing an entire string or segment. The TM matches from UI to online-help or documentation is all at the very low fuzzy match level as a UI string will usually be less than 50% of a documentation string in length.
Because of the nature of UI strings being short an often shy on context, Translation Management Systems need to be able to support the addition of two extra elements not as important to documentation translation. To support Software Localization Translation Management Systems need to be able to support the addition of Context information to source strings for translation and also the ability to support an initial extra leveraging stage whereby the String ID is used to give a guaranteed Translation Memory match.
xml:tm – a radical new approach for a Translation Platform
- Translating XML documents
XML has become one of the defining technologies that is helping to reshape the face of both computing and publishing. It is helping to drive down costs and dramatically increase interoperability between diverse computer systems. From the localization point of view XML offers many advantages:
- A well defined and rigorous syntax that is backed up by a rich tool set that allows documents to be validated and proven.
- A well defined character encoding system that includes support for Unicode.
- The separation of form and content which allows both multi-target publishing (PDF, Postscript, WAP, HTML, XHTML, online help) from one source.
Companies that have adopted XML based publishing have seen significant cost savings compared with proprietary systems. The localization industry has also enthusiastically used XML as the basis of exchange standards such as the ETSI LIS (previously LISA OSCAR) standards:
TMX* (Translation Memory eXchange)
TBX* (TermBase Exchange), SRX* (Segmentation Rules eXchange) standards
GMX/V*(Global Information Management Metrics eXchange Volume.
XLIFF* (XML Localization Interchange File Format)
TransWS* (Translation Web Services).
W3C ITS* (Internationalization Tag Set).
Another significant development affecting XML and localization has been the OASIS DITA (Darwin Information Technology Architecture) standard. DITA* provides a comprehensive architecture for the authoring, production and delivery of technical documentation. DITA was originally developed within IBM and then donated to OASIS. The essence of DITA is the concept of topic-based publication, construction and development that allows for the modular reuse of specific sections. Each section is authored independently and then each publication is constructed from the section modules. This means that individual sections only need to be authored and translated once, and may be reused many times over in different publications.
A core concept of DITA is that of reuse at a given level of granularity. Actual publications are achieved through the means of a ‘map’ that pulls together all of the required constituent components. DITA represents a very intelligent and well thought out approach to the process of publishing technical documentation. At the core of DITA is the concept the ‘topic’. A topic is a unit of information that describes a single task, concept, or reference item. DITA uses an object-orientated approach to the concept of topics encompassing the standard object oriented characteristics of polymorphism, encapsulation and message passing.
The main features of DITA are:
- Topic centric level of granularity
- Substantial reuse of existing assets
- Specialization at the topic and domain level
- Meta data property based processing
- Leveraging existing popular element names and attributes from XHTML
The basic message behind DITA is reuse: ‘write once, translate once, reuse many times’.
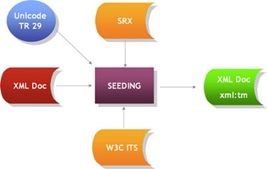
- xml:tm
xml:tm* is a radical approach to the problem of translating XML documents. In essence it takes the DITA concept of reuse and implements it at the sentence level. It does this by leveraging the power of XML to embed additional information within the XML document itself. xml:tm has additional benefits which emanate from its use. The main way it does this is through the use of the XML namespace syntax. Originally developed as a standard under the auspices of LISA OSCAR, xml:tm is now an ETSI LIS standard. In essence xml:tm is a perfect companion to DITA – the two fit together hand in glove in terms of interoperability and localization.
At the core of xml:tm is the concept of “text memory”. Text memory comprises two components:
- Author Memory
- Translation Memory
MQM: Measuring Translation Quality
Shamus Dermody http://www.xtm-intl.com
sdermody@xtm-intl.com
For many years within the Global labeling/marketing/UI/Content departments of Enterprises Worldwide and indeed within the Translation and localization industry the quality of delivered translations has been very difficult to measure and define. Choosing translation providers or individual translators that claim the highest quality process’s or have the strongest reputations has not always proved to deliver the desired and expected results.
Variable requirements and complexity make it difficult to consistently evaluate a language deliveries.
The ability to rate quality in an effective and uniform manner has long been a requirement in general in the industry but of crucial importance especially for high risk life science translation projects and translations for high risk important patient safety medical device labeling or User Interface Strings..
For example, a translation project, may have a negative reaction from an end in-country recipient client. But there can be several reasons;
- Low quality of the source content
- Translation process issues
- Subjective views of End Country reviewer
- Incomplete or low quality source or target terminology
- Software Internationalization issues ( Often caused by lack of a complete Pseudo Localization process)
- Low quality translation
Process owners need to be able to rate the performance of various translation resources at their disposal for a given language in a consistent and uniform manner.
Another example a Translation Process Owner needs to assess the relative quality of a number of translators for a given language pair. A particularly high sensitivity project may demand the highest level translation resources. A historical record from a pool of translators assessed in a uniform and managed methodology would significantly help to choose those with a consistently high quality of output.
QTLaunchPad is an EU FP7 funded project designed to help improve translation quality. The key to any form of translation (be it human or machine translation or machine translation post-editing) quality is the ability to provide consistent and measurable metrics. In the past initiatives such as the LISA QA model or JAE2450 have tried to approach this, but without a great deal of success in terms of industry acceptance, mainly due to the fact that they adopted a ‘one size fits all’ approach to all translation projects, whereas in reality there is a very wide spectrum of diversity within the type of translation task being undertaken. In addition these models have not kept up with the rapid pace of adoption of machine translation and subsequent post-editing nature of translation in this field.
The main goal of the QTLaunchPad project is establishing the concept of Measurable Quality Metrics (MQM). MQM is at the heart of QTLaunchPad and is a completely open standard. These standards were designed by a committee of industry experts and are open to public scrutiny as part of their development.
In terms of the QTLaunchPad the key participants were the German Research Center for Artificial Intelligence (DFKI), Dublin City University, the University of Sheffield and the Athena Institute for Language and Speech Processing. All leading academic institutions with access to world renowned experts in the filed including Arle Lommel who was one of the major architects of the LISA QA model.
MQM principles
MQM is based on the following key principles:
- Flexibility: MQM eschews the ‘one size fits all’ model of previous QA initiatives. It allows adapting metrics to the specific nature of the translation project to hand. Translation projects do not all have the same quality requirements or complexity. Documentation destined for automotive technicians in the workshop may have a quality requirement of ‘fit for purpose’ (technicians never read the manuals anyway, well only as a matter of last resort when all other attempts including hitting the affected item hard with a hammer have failed), whereas owner glove box instructions for a car must have no errors whatsoever. Metrics must be ‘tuneable’ along different dimensions, e.g. domain, purpose, audience. MQM provides a flexible catalogue of issues types that can be extended and adapted as required for the project to hand.
- Fairness: MQM allows for the defining the true cause of the problem. If the source text is badly and ambiguous, then the blame should not be laid at the feet of the translator. If the source text is of a low quality then it must be possible to determine this.
- Suitability: MQM is suitable for all types of translation, production methods and technologies, as well as allowing extensibility for new categories of checks.
- Comparability: MQM results must be comparable with each other even if the assessments tasks are not checking the same thing.
- Standards: MQM is based on ISO 11669 for defining QA check dimensions.
- Granularity: MQM supports various levels of granularity as required by the given project to hand.
MQM features
MQM offers the following features:
- Open Standard: MQM is a completely open and unencumbered standard.
- Flexibility: MQM provides a comprehensive and extensible list of issues types.
- Separation: MQM provides for identifying both source and target issues.
- Granularity: MQM allows for a hierarchical view of issues from high level to finely grained.
- Dimensions: MQM provides for up to eleven dimensions of QA issues, based on ISO/TS-11669, to guide users in choosing the appropriate types of issue for QA tasks.
- Backwards Compatibility: MQM supports previous QA models such as the LISA QA model or SAE J2450.
- Extensibility: MQM allows a project manager to add additional or more finely grained issue types.
The importance of MQM
Using MQM, a project manager can now provide an unambiguous, non-subjective and systematic quality assessment of the work of a translator. This takes into account any shortcomings of the original source text and can be used over time to build up a complete and comprehensive objective assessment of a linguist’s quality of work.
The functionality offers benefits for both – Alex and John alike: one being able to work with only the best, and the other one being fully appreciated for all the hard work he’s done.
MQM provides a significant improvement based on a fair and open standard of the quality of the work of individual translators.
XTM Cloud and MQM
MQM provides a significant improvement based on a fair and open standard of the quality of translation deliveries. The functionality so far has only been introduced into one commercial translation management technology – the latest release of XTM Cloud the Enterprise Translation Management System from XTM. It is available under the LQA (Linguist Quality Assurance) section and is a predefined optional workflow step in XTM.
1. Introduction
Enterprise Cloud Translation Management Systems are making an ever-increasing impact on the localization industry. This is not surprising as the cloud is a natural environment for localization: translation is by its very nature a collaborative process involving project/product managers, translators, reviewers and correctors. A centralized, coordinated system is a natural constituency for such a process.
The first generation of TMS (Translation Management Systems) and CAT (Computer Assisted Translation) systems that originated around the turn of the century were tied very much to the desktop. Based on the concept of a central server with desktop CAT tools, collaboration involved emailing files. This is both time consuming and error prone by its very nature and also results in little islands of isolated data: it is very difficult for individual actors in this scenario to share memories and terminology. For large projects involving many translators inconsistencies in translation could easily result with repeated text being translated differently by individual players.
In addition to the above, there is the problem of installing, maintaining and supporting the desktop software as well as the issue of licenses. With many of these first generation TMS systems, translators are required to use a specific CAT tool and have either to purchase it themselves or have to install it and are provided with a license for the duration of the project.
The inherent problems associated with such an architecture are:
1. The difficulties of coordination
2. A heavy project management overhead
3. The management of the desktop licenses
4. The installation, maintenance and support of desktop software
5. Isolated pockets of data
2. The Slow Death of the Desktop
In an integrated computing architecture the standard Windows PC is a very expensive and inefficient tool to buy and maintain. This is not just from the perspective of any installed software but also from the aspect of backups, security and system maintenance. PCs are notoriously virus prone, and although on the face of it they appear to not require professional IT support they are very complex to maintain. Just take the standard experience: after 6 to 9 months use desktop software on Windows PCs appears to slow down significantly. This just gets worse over time. Every PC user has experienced this. Then come Trojans and viruses and DLL hell. The more software you install on a PC the worse things become. Anti-virus software is only partially good at identifying old viruses, not new ones. From many perspectives the Windows desktop is in terminal decline, overtaken increasingly by tablets and other devices. PCs are notoriously expensive to manage and maintain outside of a tightly controlled and centralized corporate organization.
In an integrated collaborative environment desktop based software has many drawbacks and inefficiencies. Its time is quickly passing. The big advances in HTML standards and libraries have made the differences between individual browsers largely irrelevant, especially since the demise of IE 6. The browser is now becoming the main tool in which we interact with centralized systems: Managing your banking and utility transactions as well as shopping via a browser is now common place. It is now also time to translate and manage translation online.
3. The Financial Benefits
The traditional approach by software publishers regarding TMS and CAT software is the sale of a one off license. This usually includes free support for the first year, followed by 15% to 20% maintenance and support fees for subsequent years. In addition it is not uncommon to withdraw support for the version after 3 years and force users to buy an upgrade to the latest and best current version. There are many disadvantages to customers from this practice. The main one being a large one-off financial outlay. The other is the capital expenditure nature of the purchase.
Cloud translation systems are a real break-through in this respect. First off you pay monthly so there is no large initial financial outlay. Secondly, you can vary your licenses according to demand. No organization has a constant demand for translation. It is usually ‘feast or famine’: one month you are snowed under with work, the next, things can be very quiet. The ability to adjust your licenses is an ideal approach: you pay for what you need. Take the instance where all of a sudden a large project comes along that requires 30 more licenses. With the traditional TMS/CAT vendor approach you are forced to buy the additional licenses, even though in two months time you will not need them. With a cloud based system you should be able to vary your licenses from month to month or even week to week according to demand.
With the cloud approach your TMS/CAT costs are a variable element of your business, directly related to your sales, and not capital expenditure. In addition, as there is no software to install, you can be up and running with a system in minutes: all that is required is a browser and Internet connection.
4. Cloud Translation System Design
The cloud offers many advantages to the localization process. The starting point should be standards: The OASIS OAXAL (Open Architecture for XML Authoring and Localization) reference architecture standard offers an ideal standards based template for a cloud based translation system. At the heart of OAXAL are all of the existing localization standards: TMX, SRX, W3C ITS, TBX, xml:tm, Unicode and XLIFF (plus XLIFF:doc and TIPP) as well as XML itself. Designing a cloud translation process from scratch provides the opportunity to implement all relevant Localization Industry Open Standards.

In a world where over 90% of data for translation is being already generated in XML it makes sense to base the internal data structure on XML. Formats that are not in XML such as FrameMaker, HTML or RTF can be easily converted to and from XML. Having one consistent electronic form makes for a very clean, efficient and elegant design. It also allows for the creation of a data driven automaton approach based on Open Standards, where you have only one extraction and matching process rather than one for each different file format:

The use of standards is also key: TMS/CAT tool publishers have been notoriously bad at implementing and supporting standards. Take word counts as an example: the vast majority of tools each have their own proprietary way of counting words and characters. In fact a major publisher after a recent acquisition had two CAT tools producing different word counts. In addition one of the most widely adopted CAT tools had a tradition at one time of changing the word count methodology with every release. Unsurprisingly, the actual specifications of the proprietary counts are never published so cannot be verified. It is time for customers to end this nonsense by demanding support for GMX/V – the official ETSI/LIS standard for word and character counts.
The server based nature of cloud translation systems is also conducive to better and more scalable design. A current cloud translation system must be multi-tenancy and infinitely scalable. This is achieved using a SOA (Service Oriented Architecture) design where all of the individual components (analysis, extraction, translation memory management, terminology, QA and spell checking, workflow and the actual translator editor/workbench) are all implemented as individual web services based components. This provides an infinitely scalable approach where all individual components can be offloaded onto bigger and faster servers as the workload increases. Scalability must also include the ability to handle files and projects of arbitrary size: there should be no upper limits and multiple actors such as translators, reviewers and correctors must be capable of working on the same files at the same time, all sharing translation assets such as terminology and translation memory in real-time.
5. Workflow ( Translation Management System)
The cloud translation process and cloud enterprise Translation Management technology must support flexible, customizable workflow management. This must include the ability to define your own workflow steps and the ability to inform all parties involved when individual steps are overdue. It is important to allow not only sequential workflow, but also concurrent steps, such as reviewers and translators working in parallel. Transition from each workflow stage to the next must be automatic once the previous step has been completed.
6. Online CAT technology
There is very little point having a cloud translation system without the ability of translators, reviewers and correctors to work directly within a browser based environment. The recent advances in HTML and available programming libraries have made cross-browser support and dynamic features available to allow the creation of a fully feature rich, browser based translation environment.
The key is to be able to provide all of the features required:
1. Source and target text for each segment
2. History of the translation of each segment
3. Translation Memory matching
4. Machine translation suggestions
5. Comments
6. Navigation aids (next segment requiring translation, next segment with comments etc.)
7. QA plus spell checking
8. Merge segments
9. Filtering of displayed segments according to specific criteria
In other words a fully functional CAT translation environment for language professionals.

XTM Cloud CAT Technology User Interface
An online CAT tool must also allow multiple actors (project managers, translators, reviewers and correctors) to work on the same file at the same time all sharing the translation assets such as terminology and translation memory that is being generated dynamically.
Having a browser based translation workbench has many advantages over desktop tools for the translation process. The most important is that files do not have to be emailed around the workflow process: all assets are held and available centrally in real-time. Everything is constantly backed up, there are no software updates or incompatibilities to worry about. In addition the user platform is irrelevant, so there is no reliance on one single environment: the system can be access from a smart phone, tablet, Windows, Mac or Linux device.
7. The joined-up process
The key to a well-designed cloud translation process is automation. A typical non-cloud process can incur large overhead costs:

Manual Translation Process
This is due to a considerable amount of manual intervention required to process a translation project without automation:
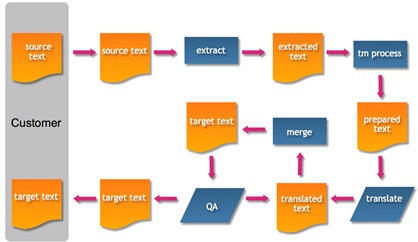
Manual Translation Process
Each of the red arrows represents manual intervention, and as well as adding to the cost, also represent a potential point of failure.
The cloud translation process provides for a fully automated environment, effectively eliminating all of the manual stages apart from the actual process of translation, review and correction: the ultimate intellectual transfer at the heart of the whole process – the bit that you can actually relate to in terms of what you are paying for:

XTM Cloud Enterprise Translation Management System process
Here all the processes in the green background represent totally automated processes. The only things that cannot be automated are the actual translation and review/correct stages which are done via the browser. In other words, everything is as automated as possible and centralized.
Other aspects of a cloud translation process are the integration with external systems such as workflow and CMS systems. Here the centralized and web services enabled nature of cloud translation systems makes seamless integration possible, such as the automatic transfer of data for translation once it is ready as well as that of the resultant translation back into the originating system.
8. Interoperability
One aspect of the cloud translation process is the ability to interoperate with other TMS/CAT tools. Here standards play a key role. The Linport initiative based on the XLIFF:doc and TIPP (Translation Interchange Package Protocol) from the Interoperability Now! initiative enables the seamless integration with other supporting TMS/CAT tools. The original XLIFF 1.2 standard allows for too many incompatible implementations to permit true interoperability as well as not catering for reference materials and terminology in the exchange.
9. Summary
The cloud translation process is an ideal fit for the localization of electronic documents, allowing for maximum real-time collaboration between all of the actors involved and reduced costs through automation. It also provides for infinite scalability and infinite project/file size as well as interactive cooperation and sharing of all translation assets.
In addition, the ‘pay-as-you-go’ nature of enterprise cloud translation Management systems such as XTM International along with flexible licensing means that the TMS/CAT costs become a direct variable part of the whole process and there is no large financial outlay for software.
The future of translation is definitely going to be cloud based as it provides the best fit for the collaborative nature of the localization process. The main technical issues holding back adoption of the cloud as a translation process, e.g. browser technology and web standards, have now been resolved. The cloud translation process is here and it is going to grow in adoption to dominate the industry as the alternatives are much less efficient.
5 Random Essentials for Successful Software Localization
1: This is Software Localization not text translation
Software Localization is more than just text translation, indeed the actual text translation is often just a factor in the overall project. Taking for granted that your product has already been internationalized, translation, localized QA both functional and linguistic, and regression stages must occur to produce a high end quality product.
2: Test plans, Test plans, Test Plans
Re-use your base language test plan during the localization process with the local languages to ensure the same level of end product Quality.
3: Provide Visual reference and/or add comments
Especially where any type of visual localization is not possible, comments in software resources that define context can really help translators. This can be difficult to appreciate especially as the meanings will seem so obvious to developers or content managers having worked on the project for the past x no of months or even years. Remember a translator will only have a very short time span on your project and no matter what their background will not have anything like the experience on your project that you have.
Having as much context information as possible on individual strings will help translators choose the right translation from the beginning. Most translation tools will allow translators to see these comments as they translate the strings. Using visual localization technologies such as Alchemy Catalyst or SDL Pasollo will provide the optimum solution here in terms of translator context, but in the absence of such technology or indeed in applications where these technologies will not provide visual localization capability, add screenshots where possible.
4: Avoid concatenation and overuse of single strings
A combination of words in English will most likely not follow the same order in most other languages. Concatenated strings and strings that are used in multiple contexts will have grammar and gender issues.
4: Compile your TM and Glossary across your Software and UI
We have all seen software or devises where terminology differs in the help and in the software. If this happens in the source language version, imagine the potential issues during the localization phase.
5: Utilize your TM and Glossary on both your Software and UI during localization
Many Localization managers and development teams expect substantial Translation Memory results from applying the software TM to the User help system. In reality though the hit rare is in the extremely low single digit percentages. Where the TM is mainly of use is in establishing a Glossary across both. The low Translation Memory hit rate is due to the way Translation Memory systems utilise segment breaks to provide matches. Software UI strings are much shorter than User Help strings and thus will provide only very low fuzzy match hits which cannot be automatically applied.
Developing Microsoft .NET Applications for Visual Localization with Alchemy Catalyst
Alchemy Catalyst’s visual view regularly calls on the Microsoft .NET Framework to create instances of complex .NET Forms and User Controls. The .NET Framework is sometimes unable to create these objects. This results in Catalyst performing a manual parse of these .NET resources so they can be rendered in Visual View. In a small number of cases, this can result in Forms or User Controls that don’t appear exactly as they would at runtime in the parent application. While localizable content is made available, missing User Interface components can sometimes lead to loss of context during the translation process.
Often the Framework is unable to create a Form or User Control because the constructor for one of these U.I. containers fails. By ‘fails’ it is meant that the constructor for the object throws an exception and this exception is unhandled by the object that raised it.
This causes unhandled exceptions in Catalyst and normally prevents a .NET Form from being correctly rendered. There are a number of suggestions for avoiding this situation. These are outlined below.
Try-Catch Blocks
Avoid unhandled exceptions: Use a ‘try-catch’ block around code in the constructor that may throw an exception.
| Sample Code | Comment |
| MyClass::MyClass(){ InitializeComponents(); OpenFile(“c:\Info.dat”);} | If a constructor refers to a file or a database that may not exist in the localization environment. The constructor may fail. Catalyst will not be able to visually render this form if the constructor fails. |
| MyClass::MyClass(){ try { InitializeComponents(); OpenFile(“c:\Info.dat”);
} catch(Exception e) { } }
|
A simple try-catch block such as this will catch the exception.Even if there is no actual handling code in the catch block, the exception does not bubble up and cause an unhandled exception in Catalyst.In the situation where the file does not exist in the localization environment, Catalyst will still be able to visually construct this form. |
Attach Event Handlers
Where appropriate: Attach event handlers to the events…
Application.ThreadException
AppDomain.CurrentDomain.UnhandledException
This will deal with these exceptions. These event handlers would not generally terminate the thread but would allow components of the user interface to continue functioning. These user interface components may be required by Alchemy Catalyst.
Call InitializeComponents() Early
Wait until after the call to InitializeComponent() before adding more logic to the constructor. The InitializeComponent() method should be complete before any code that is liable to throw an exception is added.
| Sample Code | Comment |
| MyClass::MyClass(){ OpenFile(“c:\Info.dat”); InitializeComponents();}
|
If the constructor fails before InitializeComponents() is called then no user interface components will be initialized. |
| MyClass::MyClass(){ try { InitializeComponents();
OpenFile(“c:\Info.dat”); } catch(Exception e) { } }
|
Simply placing any complicated logic after the InitializeComponents() call will ensure that the UI components are initialized before any other code may fail. |
Avoid resources that may not be present
If possible, try to avoid connecting to data sources or resources that may not exist in certain environments. When an application is installed on a client’s machine, it may be that a certain file or a database is always present (the installer may look after this). However, this may not be the case during localisation. Try to avoid dependencies such as this in the constructor or InitializeComponent() calls. This is not always possible and if not, that resource will need to be present during localization.
Public Constructors with no Arguments
For a given Form or User Control class, implement a public constructor, which takes no arguments, if one does not already exist. Such a constructor is easier for Catalyst to call.
Handle Null Parameters
In certain circumstances Catalyst can ask the .NET Framework to create objects using a constructor which takes parameters; however, when the constructor is called by Catalyst the parameters passed can be null. Ideally, code should check for the possibility of null parameters and handle any resulting exceptions gracefully.
| Sample Code | Comment |
| MyClass::MyClass(myFile File){ OpenFile(File); InitializeComponents();
}
|
When Catalyst calls a constructor that takes a parameter, it may pass in null as the parameter. Code such as this will throw an exception. An uncaught exception will result in the form not being created. |
| MyClass::MyClass(myFile File){ try {
InitializeComponents(); If(File) OpenFile(File); } catch(Exception e) } |
Checking the parameter for validity before use is a good idea and allows the form to be created without difficulty. |
Agile software Internationalization ; A developers checklist
- Externalize All Strings
- Ensure UI layout leaves sufficient room for translation related string expansion.
- Identify externalized strings which should not be translated and mark
- Provide context information on Strings (String ID, Comments)
- Ideally ensure absolutely no String Concatenation
- Utilize unique String ID’s
- Pseudo Localize (Automate this process)
Suggestions/Additions welcome!
Software internationalization, Pseudo Localization Poll Results
Alchemy Software Development conducted a number of online polls lately across approximate 300 unique webinar attendees. One of the most important of these polls was setup up to make a first step towards advancing the tried and tested process of advanced pseudo localization by gauging this process’s utilization across attendees.
The basic finding of our polls were as follows:
41% of attendees currently have a Pseudo Localization process in place 59% of attendees currently do not have a Pseudo Localization process in place
To interpret these figures though we need to look further at the attendee base.
The attendee base was a very broad mixture of professionals with CTO’s, Software Developers, Localization managers, Localization Engineers, Localization Project Managers and Translators all being in attendance. Additionally some of the above were from a Localization Service background, some freelance translators and freelance consultants and some were from development departments and localization departments within International Software Vendors.
I will follow with additional breakdown of the statistics.
Pseudo Localization Poll
An advanced Pseudo Localization Process is a requirement for Agile International Software Development!
Advanced Pseudo Localization processes are a requirement of Agile International Software Development. The software localization process will struggle greatly to keep up with the software development team sprints if high level pseudo localization processes are not applied vigorously at early development sprints. The Pseudo Localized builds then pass through a functional QA process in parallel with or indeed in place of source language builds.
Pseudo Localization enables the development of truly world ready software enabling true multilingual software sim-ship.
Pseudo localization is essentially the replacement of source text with readable pseudo-translated text. The pseudo translation language(s) can take a number of formats based mainly on the number of languages to be localised and the UI flexibility available.
The pseudo translated software UI must be readable text and therefore navigable by the software developers themselves the QA team and any others involved in the development process and for this reason a Machine Translation (MT) is not the correct process here.
Typically the minimum constituents of a pseudo language are text expansion and character substitution (“a” converts to “ä”). Text expansion, as English is one of the most concise languages. German for example can expand in areas by up to 50% creating a significant demand on UI layout creating great difficulty in PC application UI design but consider the effects of such significant expansion on a phone UI.
Pseudo languages can be quite complex and designed to include only tests for one language or many languages. The tests can include for example calculations for string length expansion based on the source string length as for example a short string might need a 100% expansion while a longer string may only need a 20% expansion.
Probably the most effective Pseudo localization process is the replacement process whereby a complete transformation to a language neutral position is made by the development team. The early development build QA takes place on Pseudo Localized builds rather than on source text builds.
The Pseudo Localization process checks your software/website for;
- Text expansion/truncation issues
- Externalisation of text (hardcoded text)
- Extraction of too much text
- Line break issues
- Some locale specific issues (date, address, numerals)
- Character encoding and font display issues
- User interface design problems
- String concatenation issues

